

s1 and the age of the gpu-poor
a new model - s1 released a week ago shows how llm breakthroughs might be made by a thousand cuts going forward
the coolest thing about this new method is that it is unironically super simple (literally in the name, 'simple test-time scaling')
i bet thousands of researchers over the past few days have gone - "wait, i could've thought of that"
what is thinking?
thinking is forcing the model to wrap some tokens within <think> tags
after it has generated tokens within those tags, the model states it's final answer
what is inference scaling?
with the release of o1, OpenAI claimed inference-time scaling laws. but what does this mean?
they showed that models perform better on benchmarks the longer you make them 'think'
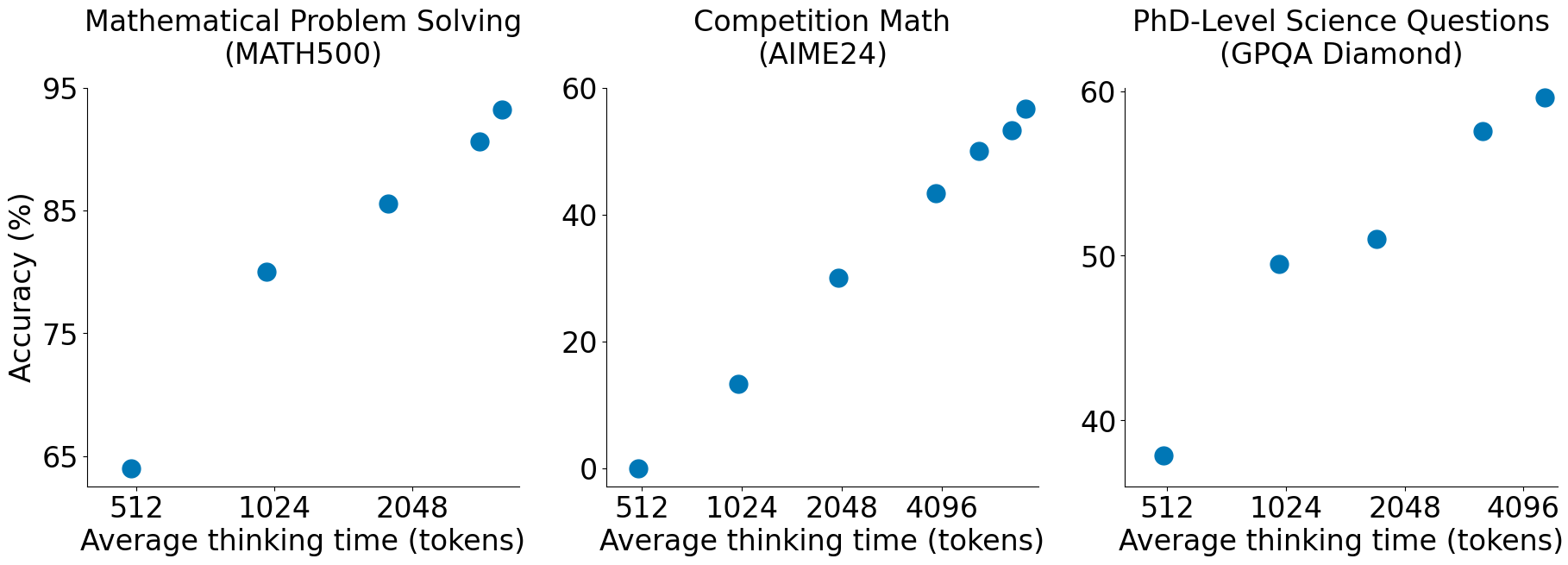
this image taken from the s1 repo, shows how more tokens -> higher accuracy over a variety of benchmarks
how do we make models think longer?
now we know what thinking is, and that models perform better the more they 'think'
s1 shows us how to make models think longer - by replacing </think> with "Wait" ... yes it is literally that simple apparently
by doing this, we don't allow the model to stop thinking and we can control the amount of tokens it generates
for all we know, o1 might be doing something similar but we can't know because OpenAI does not give us the reasoning tokens :(
this simple change allows s1 (which is built off the tiny Qwen 2.5 32B Instruct Model) to reach levels similar to o1 super efficiently

is "wait" the best we can do?
well, they tried a bunch of things, and "wait" seems to work the best| Model | AIME 2024 | MATH 500 | GPQA |
|---|---|---|---|
| No extrapolation | 50.0 | 93.0 | 57.6 |
| ------------------ | ---- | ---- | ---- |
| 2x without string | 50.0 | 90.2 | 55.1 |
| 2x “Alternatively” | 50.0 | 92.2 | 59.6 |
| 2x “Hmm” | 50.0 | 93.0 | 59.6 |
| 2x “Wait” | 53.3 | 93.0 | 59.6 | >
more evals -
| Model | # ex. | AIME 2024 | MATH 500 | GPQA |
|---|---|---|---|---|
| API only | ||||
| o1-preview | N.A. | 44.6 | 85.5 | 73.3 |
| o1-mini | N.A. | 70.0 | 90.0 | 60.0 |
| o1 | N.A. | 74.4 | 94.8 | 77.3 |
| Gemini 2.0 | N.A. | 60.0 | N.A. | N.A. |
| Flash Think. | ||||
| Open Weights | ||||
| Qwen2.5-32B-Instruct | N.A. | 26.7 | 84.0 | 49.0 |
| QwQ-32B | N.A. | 50.0 | 90.6 | 65.2 |
| r1 | > 800K | 79.8 | 97.3 | 71.5 |
| r1-distill | 800K | 72.6 | 94.3 | 62.1 |
| Open Weights and Open Data | ||||
| Sky-T1 | 17K | 43.3 | 82.4 | 56.8 |
| Bespoke-32B | 17K | 63.3 | 93.0 | 58.1 |
| s1 w/o BF | 1K | 50.0 | 92.6 | 56.6 |
| s1-32B | 1K | 56.7 | 93.0 | 59.6 |
this cost basically nothing
According to the paper -
"We perform supervised finetuning on Qwen2.5-32B-Instruct using s1K to obtain our model s1-32B using basic hyperparameters outlined in §C. Finetuning took 26 minutes on 16 NVIDIA H100 GPUs with PyTorch FSDP."
training this entire thing, ends up costing like 20$
this should encourage researchers all over the world to just start fiddling with different ideas and seeing what works
conclusion
i love things like this
literally anyone with an idea and spare change can try to extract just that bit more from tiny models. even the gpu-poorest can now try to push sota and i'm all for it
this shit is super exciting and i can't wait to see how we decide to manipulate and gaslight these black boxes of probabilities next into finally being able to count the 'r's in strawberry